5 Central tendency II
While simple averages like mean, median, and mode are widely used to summarize data, certain situations call for more specialized measures to capture the essence of a dataset. Special averages, including the geometric mean and harmonic mean, are tailored for specific contexts where the nature of the data or the relationships between data points require a different approach.
5.1 Geometric mean
The geometric mean (GM) is a specialized measure of central tendency, particularly suited for datasets involving growth rates, ratios, or percentages, such as population growth, investment returns, or interest rates. Unlike the arithmetic mean, which calculates the average by summing values, the geometric mean finds the average by multiplying values and then taking the root (typically the nth root for n values).
This approach captures the compounding effects present in the data, making the geometric mean an essential tool for accurately summarizing proportional changes or rates over time. Its utility lies in providing a more representative measure for datasets where changes are multiplicative rather than additive.
The geometric mean of a series containing n observations is the nth root of the product of the values. If \(x_{1},x_{2},\ldots, x_{n}\) are observations then
\[GM = \sqrt[n]{\prod_{i=1}^{n}x_{i}} \tag{5.1}\]
where, \(\prod_{i=1}^{n} x_i\) means the product of \(x_{1},x_{2},\ldots, x_{n}\)
\[= \left( x_1 x_2 \cdots x_n \right)^{\frac{1}{n}}\]
\[\log \text{GM} = \frac{1}{n} \log \left( x_1 x_2 \cdots x_n \right)\]
\[= \frac{1}{n} \left( \log x_1 + \log x_2 + \cdots + \log x_n \right)\]
\[= \frac{\sum_{i=1}^{n} \log x_i}{n} \tag{5.2}\]
\[\text{GM} = \text{Antilog} \left( \frac{\sum_{i=1}^{n} \log x_i}{n} \right) \tag{5.3}\]
5.1.1 Geometric mean for frequency table
\[\text{GM} = \text{Antilog} \left( \frac{\sum_{i=1}^{k} f_i \log x_i}{n} \right) \tag{5.4}\]
where, \(x_{i}\) is the ith value in the dataset and for a grouped frequency table \(x_{i}\) will be the midpoint of the ith class interval calculated as the average of upper and lower limit, \(f_{i}\) is the frequency of the ith value or class , k is the number of classes.
Example 5.1: If the weight of sorghum ear heads are 45, 60, 48, 100, 65 gms. Find the geometric mean?
| Weight of ear head (x) | log(x) |
|---|---|
| 45 | 1.653 |
| 60 | 1.778 |
| 48 | 1.681 |
| 100 | 2.000 |
| 65 | 1.813 |
| Total | 8.926 |
Solution 5.1
Here n =5
using Equation 5.3
\[=\text{Antilog}\left( \frac{8.926}{5} \right) \]
\[ =\text{Antilog}(1.785) = 60.95\] note: here \(\text{Antilog}\left( x \right) = 10^{x}\) i.e. \[\text{Antilog}\left( 1.785 \right) = \ 10^{1.785} = 60.95\]
Example 5.2: Geometric mean of a frequency distribution
| Weight of ear head (x) | Frequency(f) | log(x) | f.log(x) |
|---|---|---|---|
| 45 | 5 | 1.653 | 8.266 |
| 60 | 4 | 1.778 | 7.113 |
| 48 | 6 | 1.681 | 10.087 |
| 100 | 8 | 2.000 | 16.000 |
| 65 | 9 | 1.813 | 16.316 |
| Total | 32 | 57.782 |
Solution 5.2
Here n =32
using Equation 5.4
\[{\sum_{i = 1}^{k}{{f_{i}\log}x_{i}} = 57.782
}\]
\[{\text{GM} = \ Antilog\left( \frac{57.782}{32} \right) }\]
\[{= Antilog\left( 1.8056 \right)= 10^{1.8056} = 63.92}\]
Example 5.3: Geometric mean of a grouped frequency distribution
| Class | Mid value (x) | Frequency(f) | log(x) | f.log(x) |
|---|---|---|---|---|
| 60-80 | 70 | 5 | 1.845 | 9.225 |
| 80-100 | 90 | 4 | 1.954 | 7.817 |
| 100-120 | 110 | 6 | 2.041 | 12.248 |
| 120-140 | 130 | 8 | 2.114 | 16.912 |
| 140-160 | 150 | 9 | 2.176 | 19.585 |
| Total | 32 | 65.787 |
Solution 5.3
Here n = 32
using Equation 5.4
\[{\sum_{i = 1}^{k}{{f_{i}\log}x_{i}} = 65.787}\] \[{\text{GM} = \ Antilog\left( \frac{65.787}{32} \right)}\] \[{= Antilog\left( 2.0558 \right) = 10^{2.0558} = 113.71}\]
Merits and demerits of geometric mean
Merits
It is rigidly defined.
It is based on all the observations of the series.
It is suitable for measuring the relative changes.
It gives more weights to the small values and less weight to the large values.
It is used in averaging the ratios, percentages and in determining the rate gradual increase and decrease.
It is capable of further algebraic treatment.
Demerits
It is not easy to understand.
It is difficult to calculate.
It cannot be calculated, if the number of negative values is odd.
It cannot be calculated, if any value of a series is zero.
At times it gives a value which may not be found in the series or impractical.
5.2 Harmonic mean
Harmonic means are often used in averaging things like rates (e.g. the average travel speed given duration of several trips). Harmonic mean (HM) of a set of observations is defined as the reciprocal of the arithmetic average of the reciprocal of the given value.
Harmonic mean can be easily remembered as “reciprocal of the mean of the reciprocals”.
If \(x_{1},\ x_{2},\ldots,\ x_{n}\) are n observations then
\[\mathbf{\text{H.M}} = \frac{n}{\sum_{i = 1}^{n}\frac{1}{x_{i}}} \tag{5.5}\]
Steps in calculating Harmonic Mean (H.M)
Calculate the reciprocal (1/value) for every value.
Find the average of those reciprocals (just add them and divide by how many there are).
Then do the reciprocal of that average (=1/average).
Example 5.4: From the given data 5, 10, 17, 24, 30. calculate H.M
Solution 5.4
Here n = 5
| x | 1/x |
|---|---|
| 5 | 0.2 |
| 10 | 0.1 |
| 17 | 0.059 |
| 24 | 0.042 |
| 30 | 0.033 |
| Total | 0.434 |
using Equation 5.5
\[\mathbf{\text{H.M}} = \frac{5}{0.434} = 11.525\]
5.2.1 Harmonic mean for frequency table
\[\mathbf{\text{H.M}} = \frac{n}{\sum_{i = 1}^{k}{f_{i}\frac{1}{x_{i}}}} \tag{5.6}\]
where, \(x_{i}\) is the ith value in the dataset and for a grouped frequency table \(x_{i}\) will be the midpoint of the ith class interval calculated as the average of upper and lower limit, \(f_{i}\) is the frequency of the ith value or class , k is the number of classes.
Example 5.5: For the given data calculate the harmonic mean.
| x | 20 | 21 | 22 | 23 | 24 | 25 |
| frequency (f) | 4 | 2 | 7 | 1 | 3 | 1 |
Solution 5.5
| x | f | 1/x | f . (1/x) |
|---|---|---|---|
| 20 | 4 | 0.050 | 0.200 |
| 21 | 2 | 0.048 | 0.095 |
| 22 | 7 | 0.045 | 0.318 |
| 23 | 1 | 0.043 | 0.043 |
| 24 | 3 | 0.042 | 0.125 |
| 25 | 1 | 0.040 | 0.04 |
| 18 | 0.822 |
Here n =18
using Equation 5.6
\[\mathbf{\text{H.M}} = \frac{18}{0.822} = 21.90\]
Example 5.6: Cistern Problem-Two pipes are used to fill a cistern. Pipe A can fill the cistern in 3 hours. Pipe B can fill the cistern in 5 hours. If both pipes are opened at the same time, how long will it take to fill the cistern completely?
Solution 5.6
To solve the cistern problem, we first calculate the rate at which each pipe fills the cistern. Pipe A fills the cistern in 3 hours, so its rate is \(\frac{1}{3}\) of the cistern per hour. Pipe B fills the cistern in 5 hours, so its rate is \(\frac{1}{5}\) per hour. To find the combined rate, we add these rates together; \(\frac{1}{3} + \frac{1}{5} = \frac{8}{15}\). This means the two pipes together fill \(\frac{8}{15}\) of the cistern each hour. To find the total time, we take the reciprocal of the combined rate i.e. \(\text{Total time} = \frac{1}{\frac{8}{15}} = \frac{15}{8} = 1.875\). To convert 1.875 hours into hours and minutes, we first separate the whole number from the decimal part. 1.875 hours consists of 1 hour (the whole number) and 0.875 hours (the decimal part). Next, we convert the decimal part into minutes. Since 1 hour is equal to 60 minutes, we multiply 0.875 by 60 i.e. \(0.875 \times 60 = 52.5 \, \text{minutes}\). Rounding 52.5 minutes gives approximately 53 minutes. Thus, 1.875 hours is equivalent to 1 hour and 53 minutes.
The problem can be easily solved using the harmonic mean, the harmonic mean of two pipes is
\[ \mathbf{\text{H.M}}=\frac{2}{\frac{1}{3} +\frac{1}{5}} \]
\[= \frac{2 \cdot 3 \cdot 5}{3 + 5} = \frac{30}{8} = 3.75 \, \text{hours}\]
the harmonic mean of the pipes is 3.75 hours, and since both pipes are working together, the total time is half of that, which confirms the answer of 1 hour and 53 minutes.
Example 5.7: A car travels a certain distance from City A to City B at a speed of 60 km/h, and returns the same distance from City B to City A at a speed of 90 km/h. What is the average speed for the entire trip?
Solution 5.7
To find the average speed when traveling the same distance at two different speeds, we use the harmonic mean. The harmonic mean for the speed is \(\frac{2 \cdot S_1 \cdot S_2}{S_1 + S_2}\), where \(S_1 = 60 \, \text{km/h}\) is the speed from City A to City B, \(S_2 = 90 \, \text{km/h}\) is the speed from City B to City A.
In this case, we are calculating the average speed over the entire round trip. The harmonic mean is used because it accounts for the fact that traveling at different speeds over the same distance results in an overall average speed that is closer to the lower of the two speeds, rather than simply averaging the two speeds.
Now, applying the harmonic mean formula:
\(S_{\text{avg}} = \frac{2 \cdot 60 \cdot 90}{60 + 90} = \frac{10800}{150} = 72 \, \text{km/h}\)
So, the average speed for the entire trip is 72 km/h.
Merits and demerits of harmonic mean
Merits
It is rigidly defined.
It is defined on all observations.
It is amenable to further algebraic treatment.
It is the most suitable average when it is desired to give greater weight to smaller and less weight to the larger ones.
Demerits
It is not easily understood.
It is difficult to compute.
It is only a summary figure and may not be the actual item in the series.
It gives greater importance to small items and is therefore, useful only when small items have to be given greater weightage.
It is rarely used in grouped data.
5.3 AM, GM or HM ?
The arithmetic mean (AM), geometric mean (GM), and harmonic mean (HM) are termed as Pythagorean means. The Pythagorean means refer to three specific types of means that were known to the ancient Greek mathematicians, particularly to Pythagoras and his followers. Choosing the right average depends on what you’re measuring and how the data behaves. Let’s break it down step by step in a simple way:
Arithmetic Mean (AM)
The arithmetic mean is the most common type of average. You use it when the values in your data add together in a straightforward way. This is suitable for quantities like:
- Heights or weights
- Lengths or distances
- Marks in exams
For example, if you want to find the average height of students in a class, you add up all the heights and divide by the number of students. The arithmetic mean gives a meaningful average because height or weight adds linearly.
Harmonic Mean (HM)
The harmonic mean is useful when you are working with rates, ratios, or situations where quantities add up as reciprocals. Some examples include:
- Speeds (distance per unit time)
- Capacitors in a series circuit
- Rates like fuel efficiency or cost per unit
For instance, imagine you are driving the same distance at different speeds. If you want to find the average speed for the entire trip, the harmonic mean is the best choice. This is because speeds relate inversely to time when you go faster, you take less time, and vice versa.
Geometric Mean (GM)
The geometric mean is the right choice when your data involves multiplication or compounding, such as:
- Growth rates (like population growth or interest rates)
- Percentages (like inflation rates)
- Ratios
For example, if you have annual interest rates for 10 years and want to find a single rate that represents the same total growth over that period, the geometric mean gives you the answer. It works by multiplying the rates and taking the root, which accounts for the compounding effect.
Here’s a simple example to understand how the geometric mean works. Suppose you invest Rs.100, and your investment changes over three years as follows: in the first year, it grows by 10%, represented by a growth factor of 1.10; in the second year, it grows by 20%, represented by 1.20; and in the third year, it drops by 10%, represented by 0.90. To find a single rate that would give the same overall growth over the three years, you multiply the growth factors: \(1.10 \times 1.20 \times 0.90 = 1.188\). Then, take the cube root (since there are three years): \(\sqrt[3]{1.188} \approx 1.059\). This gives a geometric mean rate of approximately 1.059, or 5.9% per year. In other words, if your Rs. 100 investment grew steadily at a rate of 5.9% each year, it would result in the same total growth over three years, leaving you with about Rs. 118.80 at the end.
Key Takeaways
1. Use Arithmetic Mean when values combine directly, like adding lengths or weights.
2. Use Harmonic Mean for rates or quantities that work reciprocally, like speed or resistance.
3. Use Geometric Mean for data involving multiplication or compounding, like growth rates or percentages.
By understanding the relationship between the data and the type of average, you can choose the most meaningful measure for your analysis.
5.4 Relation between AM, GM and HM
The formula for the relation between AM, GM, HM is the product of arithmetic mean and harmonic mean is equal to the square of the geometric mean. This can be presented here in the form of Equation 5.7
\[\mathbf{\text{AM}}\mathbf{\times}\mathbf{\text{HM}}\mathbf{=}\mathbf{\text{GM}}^{\mathbf{2}} \tag{5.7}\]
also
\[\mathbf{AM \geq GM \geq HM} \tag{5.8}\]
5.4.1 Geometric illustration
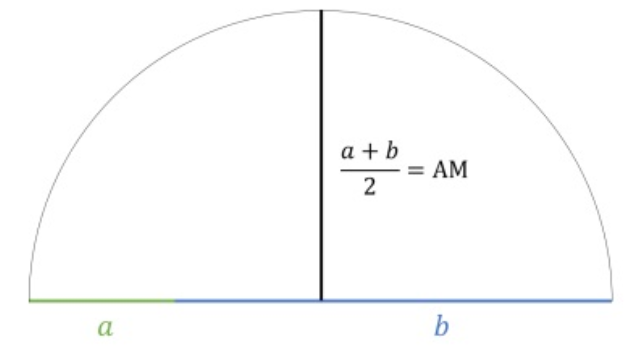
Consider two numbers a and b. See Figure 5.1 a semi circle can be drawn with diameter a+b. Then its radius is half the diameter, which will be the arithmetic mean \(\frac{a+b}{2}\).
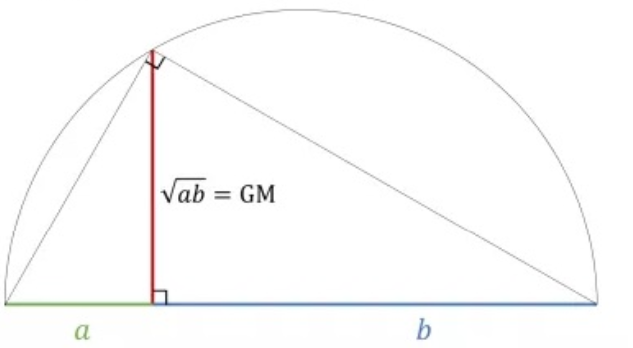
The geometric mean is the length of the perpendicular where a and b meet, which is never larger than the radius of the circle as illustrated in Figure 5.2
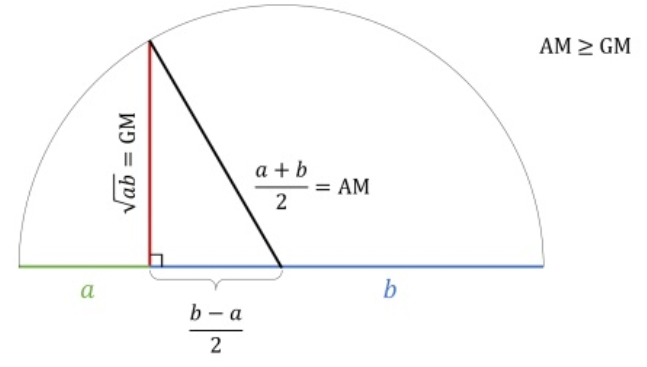
Now draw a line from the top of red line which is the GM in Figure 5.2 to the center of the circle. Now that line is the radius of the circle, so it is equal to AM, which is now the hypotenuse of the newly formed triangle with GM as the leg of the triangle. So from Figure 5.3 it is clear that
\[\mathbf{AM \geq GM} \tag{5.9}\]
Now if we draw an altitude to the hypotenuse as shown in Figure 5.3, the upper length on the hypotenuse is the harmonic mean . We can now consider another triangle where HM is a leg and the GM is the hypotenuse, this shows the GM is never smaller than the HM. So \[\mathbf{GM \geq HM} \tag{5.10}\]
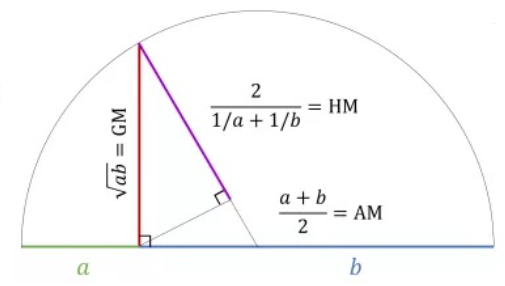
Now from Equation 5.9 and Equation 5.10 it is clear that \(\mathbf{AM \geq GM \geq HM}\)
5.5 Positional averages
Positional averages are measures derived directly from the values in a dataset. These averages are based on the position of the values within the series and are used to represent the overall dataset or highlight specific positional characteristics.
The median although a simple average is also a positional average that represents the middle value of an ordered dataset, making it a central point of reference. Similarly, the mode, which identifies the most frequently occurring value in the dataset, is also a positional average since it is directly taken from the series.
The other common positional averages include percentiles, quartiles, and deciles, which divide the data into equal parts to analyze its distribution.
In contrast, measures like the arithmetic mean, geometric mean, and harmonic mean are referred to as mathematical averages, as they are calculated through specific mathematical operations rather than being derived from the data’s positional properties.
5.6 Quartiles
The median divides a dataset into two equal halves. Similarly, it is possible to divide a dataset into more than two parts. When an ordered dataset is divided into four equal sections, the points that mark these divisions are called quartiles.
The first or lower quartile (\(\mathbf{Q}_{\mathbf{1}}\)) is a value that has one fourth, or 25% of the observations below its value.
The second quartile (\(\mathbf{Q}_{\mathbf{2}}\)), has one-half, or 50% of the observations below its value. The second quartile is equal to the median.
The third or upper quartile, (\(\mathbf{Q}_{\mathbf{3}}\)), is a value that has three-fourths, or 75% of the observations below it. If there are n items in a dataset then
\[Q_1 = \left( \frac{n + 1}{4} \right)^{\text{th}} {\text{item}} \tag{5.11}\]
\[Q_3 = \left( \frac{3(n + 1)}{4} \right)^{\text{th}} {\text{item}} \tag{5.12}\]
Calculations of quartiles are explained using the example below. See in the example the procedure followed when a fraction appear in the calculation.
Example 5.8: Compute quartiles for the data 25, 18, 30, 8, 15, 5, 10, 35, 40, 45.
Solution 5.8
First arrange the data in ascending order
5, 8, 10, 15, 18, 25, 30, 35, 40, 45
here n = 10
using Equation 5.11 and Equation 5.12
\(Q_{1} = \left( \frac{10 + 1}{4} \right)^{th}\) = 2.75th item; when such a fraction appears we use the following procedure
$Q_{1} = $2.75th item = 2nd item + 0.75(3rd item - 2nd item)
So from the given data \(Q_{1}\) = 8+0.75(10– 8) = 9.5, also \(Q_{2}\) is the median, here \(Q_{2}\) = (18+25)/2 = 21.5
\(Q_{3} = \left(\frac{3(10 + 1)}{4} \right)^{th}\) = 8.25th item = 8th item + 0.25(9th item - 8th item) = 35+0.25(40-35) = 36.25
Quartiles of a discrete frequency data
The following steps explain how to calculate quartiles for discrete frequency data
Find cumulative frequencies.
Find \(\left( \frac{n + 1}{4} \right)\).
See in the cumulative frequencies, the value just greater than \(\left(\frac{n + 1}{4}\right)\), then the corresponding value of \(x\) is \(Q_{1}\).
Find \(\left( \frac{3(n + 1)}{4}\right)\).
See in the cumulative frequencies, the value just greater than \(\left(\frac{3(n + 1)}{4}\right)\), then the corresponding value of \(x\) is \(Q_{3}\).
Example 5.9: Compute quartiles for the data given below
| x | 5 | 8 | 12 | 15 | 19 | 24 | 30 |
| f | 4 | 3 | 2 | 4 | 5 | 2 | 4 |
Solution 5.9
| x | f | cf |
|---|---|---|
| 5 | 4 | 4 |
| 8 | 3 | 7 |
| 12 | 2 | 9 |
| 15 | 4 | 13 |
| 19 | 5 | 18 |
| 24 | 2 | 20 |
| 30 | 4 | 24 |
Here n =24
\(\left( \frac{n + 1}{4} \right)\) = \(\left( \frac{25}{4} \right)\) = 6.25
The cumulative frequency value just greater than 6.25 is 7, the
\({x}\) value corresponding to cumulative frequency 7 is 8. So \({Q}_{1}\) = 8
\(\left( \frac{3(n + 1)}{4} \right)\) = \(\left( \frac{3 \times 25}{4} \right)\) = 18.75
The cumulative frequency value just greater than 18.75 is 20, the
\(\mathbf{x}\) value corresponding to cumulative frequency 20 is 24. So \({Q}_{3}\) = 24
Quartiles of a grouped frequency data
Below it is explained steps in calculating quartiles for a continuous frequency data
Find cumulative frequencies.
Find \(\left( \frac{n}{4} \right)\).
See in the cumulative frequencies, the value just greater than\(\left( \frac{n}{4} \right)\), and then the corresponding class interval is called first quartile class.
Find \(3\left( \frac{n}{4} \right)\).
See in the cumulative frequencies the value just greater than \(33\left( \frac{n}{4} \right)\)then the corresponding class interval is called 3rd quartile class. Then apply the respective formulae
\[Q_1 = l_1 + \frac{\frac{n}{4} - m_1}{f_1} \times c_1 \tag{5.13}\]
\[Q_3 = l_3 + \frac{3 \left( \frac{n}{4} \right) - m_3}{f_3} \times c_3 \tag{5.14}\]
where, \(l_{1}\) = lower limit of the first quartile class
\(f_{1}\) = frequency of the first quartile class
\(c_{1}\) = width of the first quartile class
\(m_{1}\) = cumulative frequency preceding the first quartile class
\(l_{3}\)= 1ower limit of the 3rd quartile class
\(f_{3}\)= frequency of the 3rd quartile class
\(c_{3}\)= width of the 3rd quartile class
\(m_{3}\) = cumulative frequency preceding the 3rd quartile class
Example 5.10: Find the quartiles for the grouped frequency data given
| Class | frequency | cumulative frequency |
|---|---|---|
| 0–10 | 11 | 11 |
| 10–20 | 18 | 29 |
| 20–30 | 25 | 54 |
| 30–40 | 28 | 82 |
| 40–50 | 30 | 112 |
| 50–60 | 33 | 145 |
| 60–70 | 22 | 167 |
| 70–80 | 15 | 182 |
| 80–90 | 12 | 194 |
| 90–100 | 10 | 204 |
Solution 5.10
\(\left( \frac{n}{4} \right)\) = \(\frac{204}{4}\) = 51
The cumulative frequency value just greater than 51 is 54 so the class 20-30 is the 1st quartile class
using Equation 5.13
\[Q_1 = 20 + \frac{51 - 29}{25} \times 10 = 28.8\]
\(3\left( \frac{n}{4} \right)\)= \(3 \times \frac{204}{4}\) = 153
The cumulative frequency value just greater than 153 is 167 so the class 60-70 is the 3rd quartile class.
using Equation 5.14
\[Q_1 = 60 + \frac{153 - 145}{22} \times 10 = 63.63\]
5.7 Percentiles
Percentiles divide an ordered dataset into 100 equal parts, with each part containing 1% of the observations. The pth percentile, denoted as \(P_p\), is the value below which x percent of the data falls.
For example:
- The \(\mathbf{P}_{\mathbf{50}}\), 50th percentile is equivalent to the median, representing the middle value of the dataset.
- The \(\mathbf{P}_{\mathbf{25}}\), 25th percentile corresponds to the first quartile (\(Q_1\)), which marks the lower 25% of the data.
- The \(\mathbf{P}_{\mathbf{75}}\), 75th percentile is the third quartile (\(Q_3\)), indicating that 75% of the data falls below this value.
For raw data, first arrange the n observations in increasing order. Then the xth percentile is given by
\[P_p = \left( \frac{p(n + 1)}{100} \right)^{\text{th}} \text{ item} \tag{5.15}\]
Percentiles of discrete frequency data
To calculate percentiles for discrete frequency data, follow these steps which is similar to that of quartiles:
Find the cumulative frequencies.
Find the position of the percentile. For the \(p\)-th percentile, calculate the position using the formula: \[ P_p = \left( \frac{p(n + 1)}{100} \right) \] where \(p\) is the percentile and \(n\) is the total number of data points.
Identify the value in the cumulative frequencies.
find the cumulative frequency that is just greater than or equal to the calculated position \(P_p\). The corresponding value of \(x\) is the \(p\)-th percentile.
For example, to find the first percentile (\(P_1\)): - Calculate \(P_1 = \left( \frac{1(n + 1)}{100} \right)\). - Locate the cumulative frequency that is just greater than \(P_1\), and the corresponding value of \(x\) is \(P_1\).
Percentiles of a grouped frequency data
Calculation of percentile is very much similar to that of quartile. For a frequency distribution the pth percentile is given by following steps
Find cumulative frequencies.
Find \(\left( \frac{p.n}{100} \right)\).
See in the cumulative frequencies, the value just greater than \(\left( \frac{p.n}{100} \right)\) and then the corresponding class interval is called Percentile class.
Use the following formula
\[P_p = l + \frac{\left( \frac{p \times n}{100} \right) - cf}{f} \times c \tag{5.16}\]
where,
\({l}\) = lower limit of the percentile class
\({cf}\) = cumulative frequency preceding the percentile class
\({f}\) = frequency of the percentile class
\({c}\) = class interval
\({n}\) = total number of observations
Example 5.11: Compute \({P}_{25}\) and \({P}_{75}\) for the data 25, 18, 30, 8, 15, 5, 10, 35, 40, 45.
Solution 5.11
First arrange the data in ascending order
5, 8, 10, 15, 18, 25, 30, 35, 40, 45
Here n = 10
\(P_{25} = \left( \frac{25(10 + 1)}{100} \right)^{\text{th}}\) = 2.75th item
\(P_{25}\) = 2.75th item = 2nd item + 0.75(3rd item – 2nd item)
So from the given data \(P_{25}\) = 8+0.75(10– 8) = 9.5
\(P_{75} = \left( \frac{75(10 + 1)}{100} \right)^{\text{th}}\) = 8.25th item
i.e. \(P_{75} = \left( 75 \times \frac{10 + 1}{100} \right)^{th}\) = 8.25th item = 8th item + 0.25(9th item –8th item) = 35+0.25(40-35) = 36.25
Data in Example 5.11 is same as Example 5.8; it can be seen that \(P_{25} = Q_{1}\) & \(P_{75} = Q_{3}\) always
Try yourself
Find \(P_{25}\), \(P_{50}\) & \(P_{75}\) for Example 5.9 & 5.10; verify that \(P_{50} = Q_{2}\), \(P_{25} = Q_{1}\) & \(P_{75} = Q_{3}\)
5.8 Deciles
Deciles consist of 9 points that divide an ordered dataset into ten equal parts. The d th decile is denoted as \(D_d\). It is important to note that the median is the 5th decile.
\[D_d = \left( \frac{d(n + 1)}{10} \right)^{\text{th}} \text{ item} \tag{5.17}\]
where, \(d\) is the decile number (e.g., \(d = 1\) for the first decile, \(d = 9\) for the ninth decile), and \(n\) is the total number of data points.
Deciles of discrete frequency data
To calculate deciles for discrete frequency data, follow these steps which are similar to that of percentiles:
Find the cumulative frequencies.
Find the position of the decile.
For the \(d^{th}\) decile, calculate the position using the formula:
\[D_d = \left( \frac{d(n + 1)}{10} \right)\]
Identify the value in the cumulative frequencies.
Find the cumulative frequency that is just greater than or equal to the calculated position \(D_d\). The corresponding value of \(x\) is the \(d^{th}\) decile.
For example, to find the first decile (\(D_1\)): - Calculate \(D_1 = \left( \frac{1(n + 1)}{10} \right)\). - Locate the cumulative frequency that is just greater than \(D_1\), and the corresponding value of \(x\) is \(D_1\).
Deciles of a grouped frequency data
For a frequency distribution the dth decile is given by following steps
Find cumulative frequencies.
Find \(\left( \frac{d.n}{10} \right)\).
See in the cumulative frequencies, the value just greater than\(\left( \frac{d.n}{10} \right)\)and then the corresponding class interval is called decile class.
Use the following formula
\[D_d = l + \frac{\left( \frac{d \times n}{10} \right) - cf}{f} \times c \tag{5.18}\]
where,
\(l\) = lower limit of the decile class
\({cf}\) = cumulative frequency preceding the decile class
\({f}\) = frequency of the decile class
\({c}\) = class interval
\({n}\) = total number of observations
Try yourself
Find \(\text{D}_{5}\) for Example 5.9, 5.10 & 5.11; verify that \({D}_{5} = {Q}_{2} = {P}_{50} = median\)
The harmonic mean and the perfect fourth
The harmonic mean a term derived from the ancient Greeks, particularly associated with Pythagoras or his followers. The harmonic mean is closely related to musical intervals, specifically the perfect fourth. In music theory, an octave change upwards corresponds to a doubling of the frequency (a 1:2 ratio). The harmonic mean of 1 and 2, which is \(\frac{4}{3}\), defines the frequency ratio for the perfect fourth, making it a crucial concept in understanding musical harmony and acoustics.
“The best thing about being a statistician is that you get to play in everybody else’s backyard”. – John Tukey